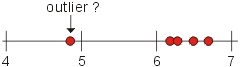Dixon's Q-test:
Detection of a single outlier
Theory In a set of replicate
measurements of a physical or chemical quantity, one or more of the obtained
values may differ considerably from the majority of the rest. Usually, an outlier is
defined as an observation that is generated from a different model or a
different distribution than was the main "body" of data. The rejection of suspect observations must be based exclusively on an objective
criterion and not on subjective or intuitive grounds. The Dixon's Q-test
is the simpler test of this type and
it is usually the only one described in textbooks of Analytical Chemistry in the
chapters of data treatment. This test allows us to examine if one (and only one) observation from a small set of
replicate observations (typically 3 to 10) can be "legitimately" rejected or not. Q-test is based on the
statistical distribution of "subrange ratios" of ordered data
samples, drawn from the same normal population. How the Q-test is applied The
test is very simple and it is applied as follows: (1) The N values comprising
the set of observations under examination are arranged in ascending order: x1 < x2 < . . . < xN (2) The statistic experimental
Q-value (Qexp) is calculated.
(3) The obtained Qexp
value is compared to a critical Q-value (Qcrit) found in tables. This
critical value should correspond to the confidence level (CL) we have
decided to run the test (usually: CL=95%). Note: Q-test is a significance test. For
more information on terms and concepts related to significance tests (e.g. null
hypothesis, confidence levels, probabilities of type I and type II errors), see
the applet: Student's
t-test: Comparison of two means. (4) If Qexp > Qcrit,
then the suspect value can be characterized as an outlier and it can be
rejected, if not, the suspect value must be retained and used in all subsequent
calculations.
The null
hypothesis associated to Q-test is as follows: "There is no a significant difference
between the suspect value and the rest of them, any differences must be
exclusively attributed to random errors". A table containing the
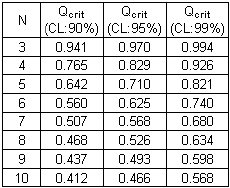
critical Q values for CL 90%, 95% and 99% and N=3-10 is given below [from: D.B.
Rorabacher, Anal. Chem. 63 (1991) 139] Table
of critical values of Q
Typical example The following replicate observations were obtained during a measurement and they are arranged in ascending order: These values can be represented by the following
dotplot:
Can we reject observation 4.85 as an outlier at a 95% confidence level? Answer: The corresponding Qexp value is: Qexp
= (6.18 - 4.85) / (6.69 - 4.85) = 0.722. Qexp is greater than Qcrit
value (=0.710, at CL:95% for N=5). Note: At confidence level 99%, the suspect
observation cannot be rejected, hence the probability of erroneous rejection is
greater than 0.01. A general comment on the
rejection of outliers All data rejection tests must
be judiciously used. Some statisticians object to the rejection of data from any
small size data sample, unless it is solidly known that something went wrong during the corresponding
measurement. Other recommend the accommodation of outliers and not their rejection,
i.e. they suggest to include deviant values in all subsequent calculations but with
reduced statistical weight (Winsorized methods). It
should be also stressed that the use of Q-test is increasingly discouraged in favor of other more
robust methods. One such method is the Huber
method, which takes into consideration all data present within the set, and not
only three as in the case of Q-test. Applet
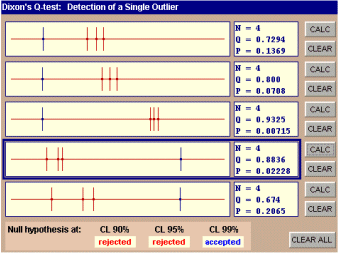
With
this applet we can experiment with small data samples (Ν
= 3
to 10), which can be easily produced and displayed on each one of the 5
dotplot-areas.
The
outcome of the test is reported at the lower part of applet working area:
The
report (in the present example) is as follows: The null hypothesis is rejected
at CL levels 90% and 95%, whereas it is accepted at CL 99%. However,
this applet can give the actual value of p and this value is shown
(as P) in the small window next to the dotplot along with N and Q. By
clicking on the "CLEAR" button the dotplot is cleared and a new data
sample can be created and examined as previously described.
|